ML Challenge: Human Pose Estimation
In this project we will try to learn machine learning by applying it to predict human pose from a RGB image. Human pose estimation is an interesting area of machine learning with a lot of applications like.
- Artificial coach for learning new motor skills, sports, etc.
- A gym assistant to guide you with your exercises.
- Artificial physiotherapist for helping you get back from a musculoskeletal problem.
- Gesture interface for a more natural way of interacting with your computer.
- Personal assistant for improving your posture.
- Analysis of nonverbal communication.
- Controlling virtual characters.
These are some applications that excites me but there are many more.
We will start with very simple model and slowly add new ideas to make it better. You can find all the code on Github
Model 1 - SimplePose
In this simplest model we will use a simple convolutional neural network that are used for image classification but instead of predicting the class of the object present we will try to predict the x, y coordinates of the joints.
Architecture
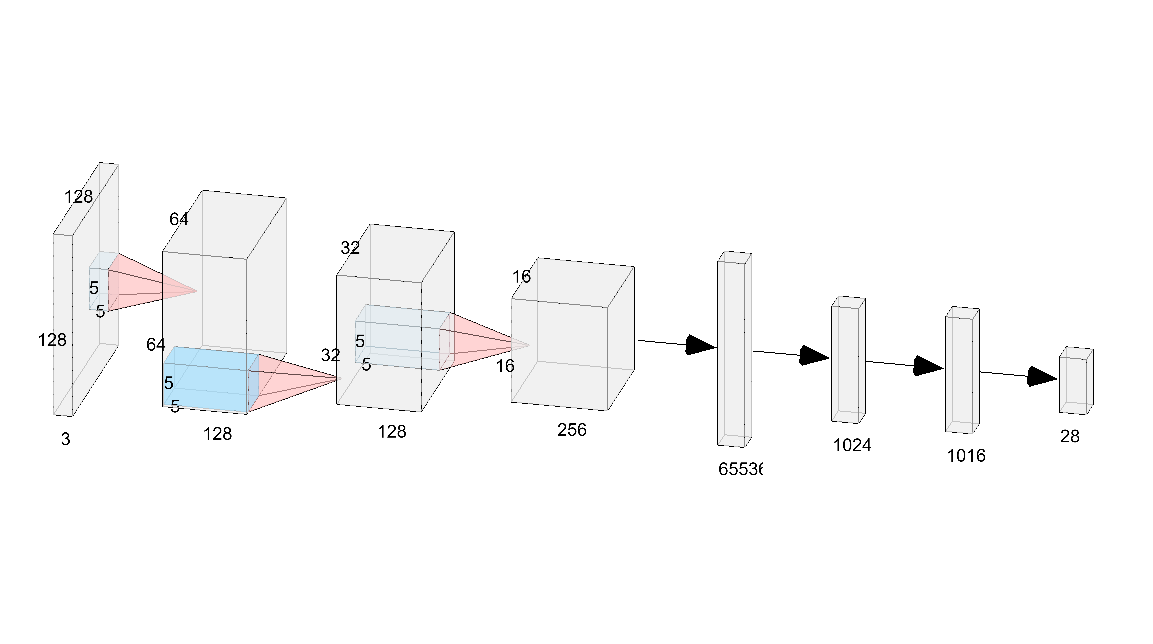
Code
class SimplePose(nn.Module):
def __init__(self):
super(SimplePose, self).__init__()
self.conv1 = nn.Conv2d(3, 128, 5, padding=2)
self.conv2 = nn.Conv2d(128, 128, 5, padding=2)
self.conv3 = nn.Conv2d(128, 256, 5, padding=2)
self.fc1 = nn.Linear(in_features=256*16*16, out_features=1024)
self.fc2 = nn.Linear(in_features=1024, out_features=1024)
self.fc3 = nn.Linear(in_features=1024, out_features=28)
def forward(self, x):
# x -> [-1, 3, 128, 128]
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
# x -> [-1, 32, 64, 64]
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
# x -> [-1, 32, 32, 32]
x = F.relu(self.conv3(x))
x = F.max_pool2d(x, 2)
# x -> [-1, 64, 16, 16]
# x -> [-1, 64, 16, 16]
x = x.view(-1, 256*16*16)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return xResults
The model is trained on the extended LSP dataset.
To test the model I used images from the original LSP dataset. Here are some results from the model.
Test 1

Test 2

Test 3

As you can see the model is able to get the approximate pose right but is not that accurate.
Improvements
One simple improvement that we can make to this model is that we could take the initial points predicted by this model and then crop the original image around those points and then train a second neural network to make a better prediction around that point.
This will give us the approach used by DeepPose model in this paper
Model 2 - HmapPose
Regressing directly to x, y coordinates is hard. In this model we will try to solve that problem by using a fully convolutional architecture to generate heat maps of where the points are in the image.
Architecture
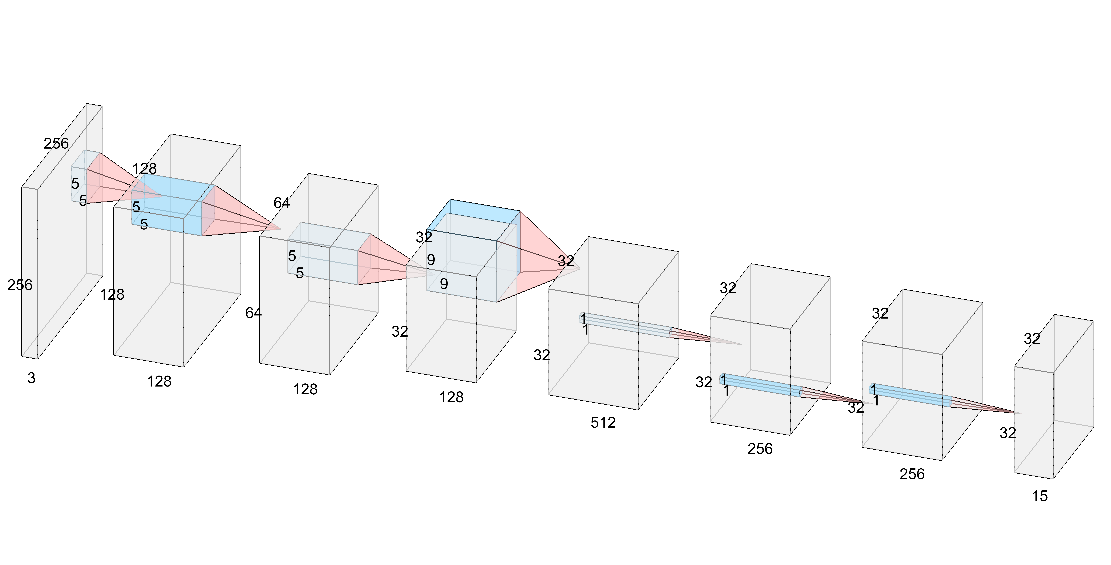
Code
class HmapPose(nn.Module):
def __init__(self):
super(HmapPose, self).__init__()
self.conv1 = nn.Conv2d(3, 128, 5, padding = 2)
self.conv2 = nn.Conv2d(128, 128, 5, padding = 2)
self.conv3 = nn.Conv2d(128, 128, 5, padding = 2)
self.conv33 = nn.Conv2d(128, 512, 9, padding = 4)
self.conv4 = nn.Conv2d(512, 256, 1)
self.conv5 = nn.Conv2d(256, 256, 1)
self.conv6 = nn.Conv2d(256, 15, 1)
def forward(self, x):
# x -> [-1, 3, 256, 256]
x = F.relu(self.conv1(x))
# x -> [-1, 32, 256, 256]
x = F.max_pool2d(x, 2)
# x -> [-1, 32, 128, 128]
x = F.relu(self.conv2(x))
# x -> [-1, 32, 128, 128]
x = F.max_pool2d(x, 2)
# x -> [-1, 32, 64, 64]
x = F.relu(self.conv3(x))
# x -> [-1, 64, 64, 64]
x = F.max_pool2d(x, 2)
# x -> [-1, 64, 32, 32]
x = F.relu(self.conv33(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = F.tanh(self.conv6(x))
# x -> [-1, 14, 32, 32]
return xResults
Test 1

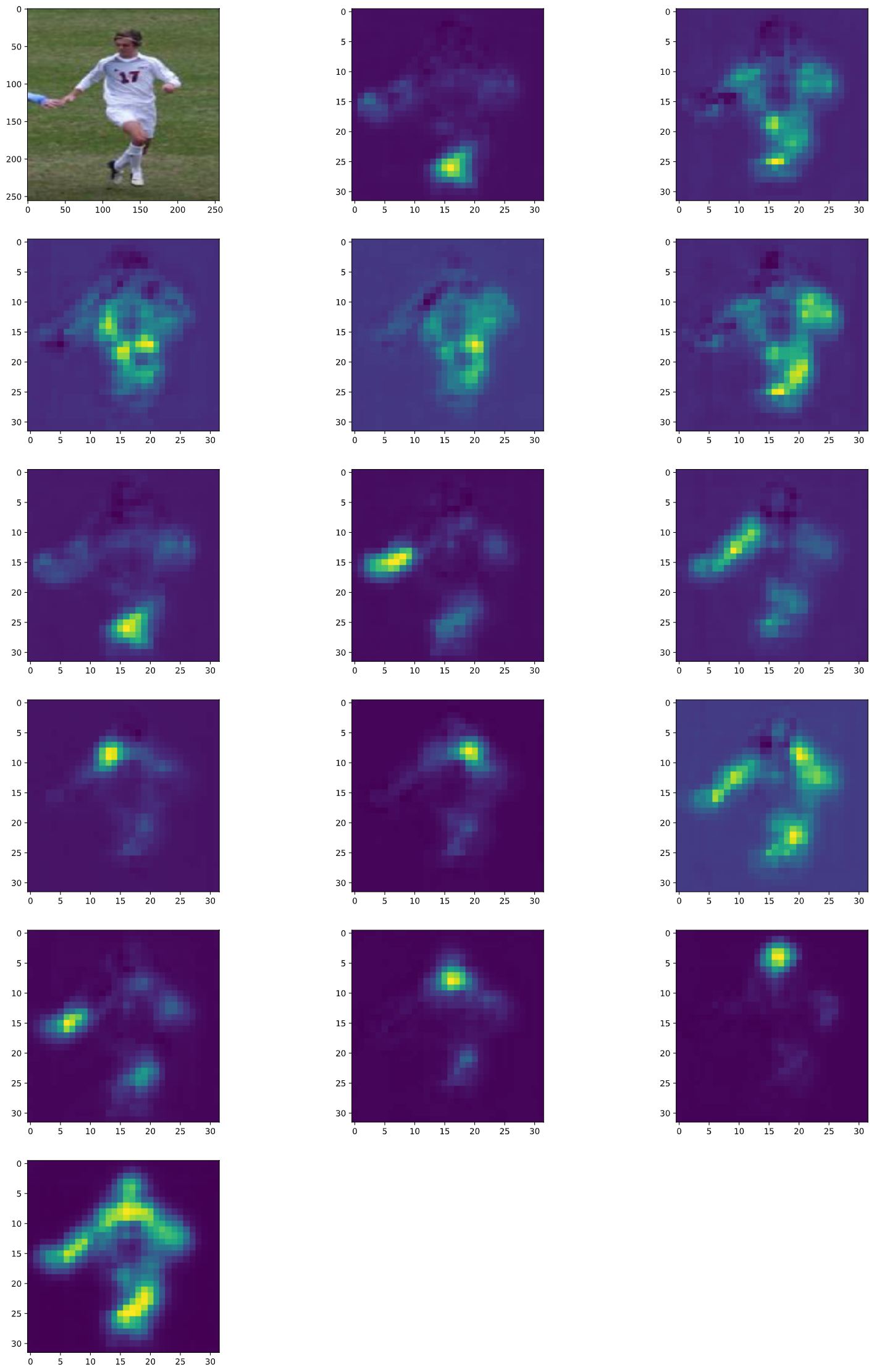
Test 2
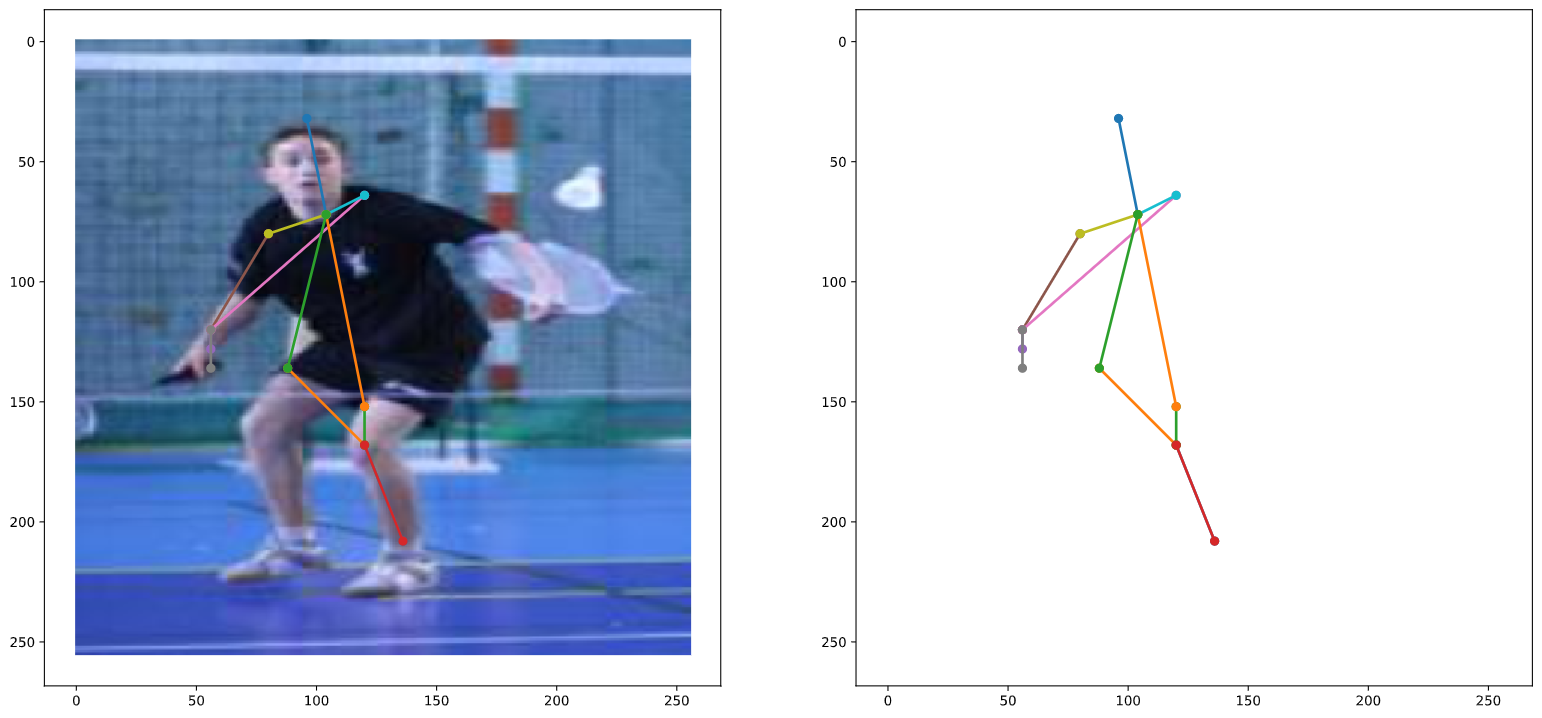
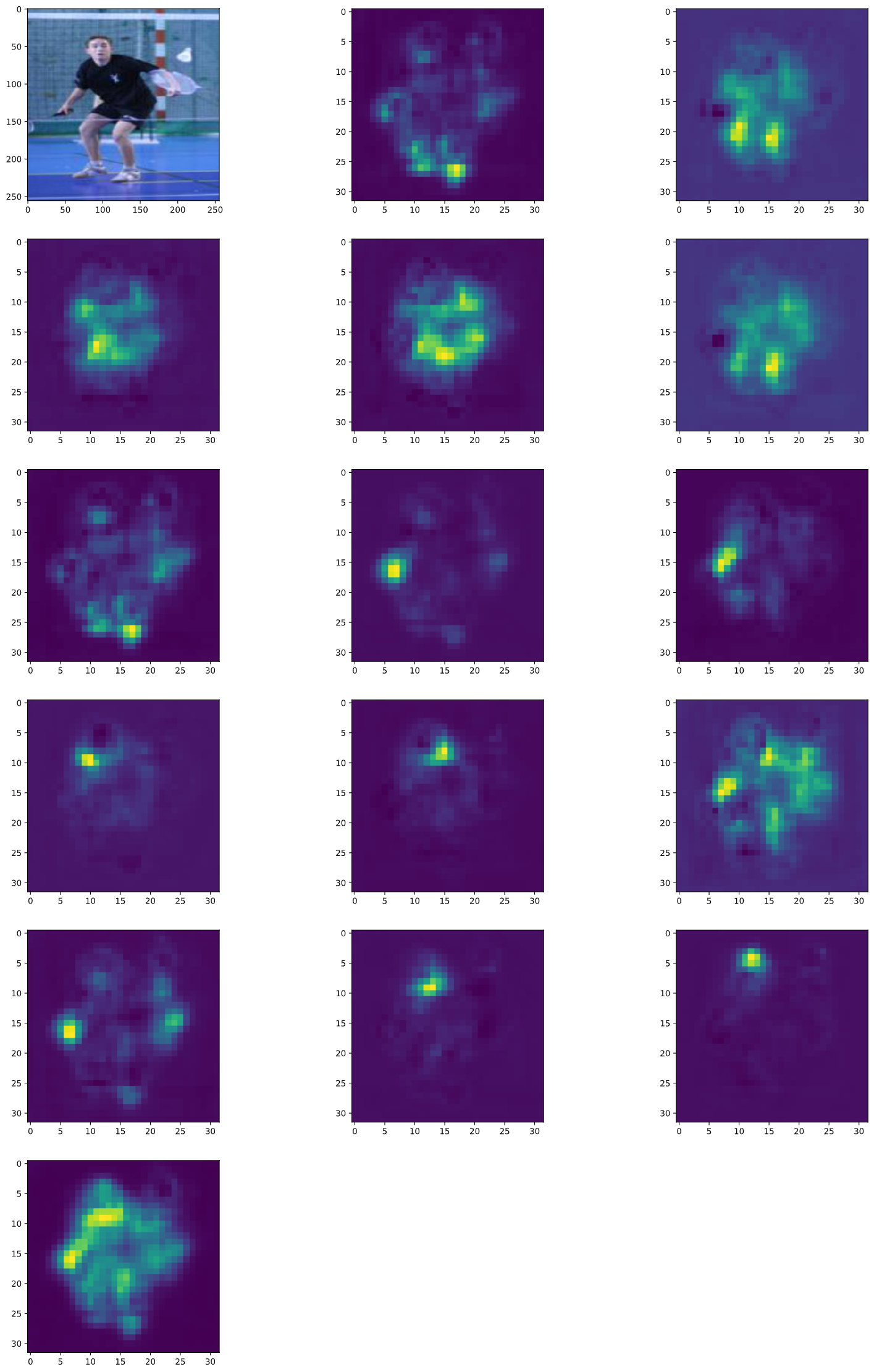 Heatmap Order:
- Right ankle
- Right knee
- Right hip
- Left hip
- Left knee
- Left ankle
- Right wrist
- Right elbow
- Right shoulder
- Left shoulder
- Left elbow
- Left wrist
- Neck
- Head top
- All Joints
Heatmap Order:
- Right ankle
- Right knee
- Right hip
- Left hip
- Left knee
- Left ankle
- Right wrist
- Right elbow
- Right shoulder
- Left shoulder
- Left elbow
- Left wrist
- Neck
- Head top
- All Joints
As you can see, this model has difficulty distinguishing symmetrical body parts like knee, hips, elbow etc. It is very hard to differentiate between left and right knee if you are just looking at a single knee and a small area around it.
Improvements
We can use the same approach we used previously and use the model predictions to crop the input image around that point and use a second neural network to improve upon that prediction.
We can further improve by using the lower level layer activation from the original neural network around the predicted points as the input to the second network. This will prevent redundant computations and improve generalizations.
We can also provide different rescaled versions of the original image to the network to help it deal with different scales in the dataset.
Doing all those improvements will give us the approach used by this paper
Model 3 - Convolutional Pose Machine
This is a model designed to specifically solve the problem of pose estimation. This model uses a multistage architecture. The first stage predicts the approximate joint location heat map and then in the next stage looks at a bigger context and refines those results. This model comes from this paper
Architecture
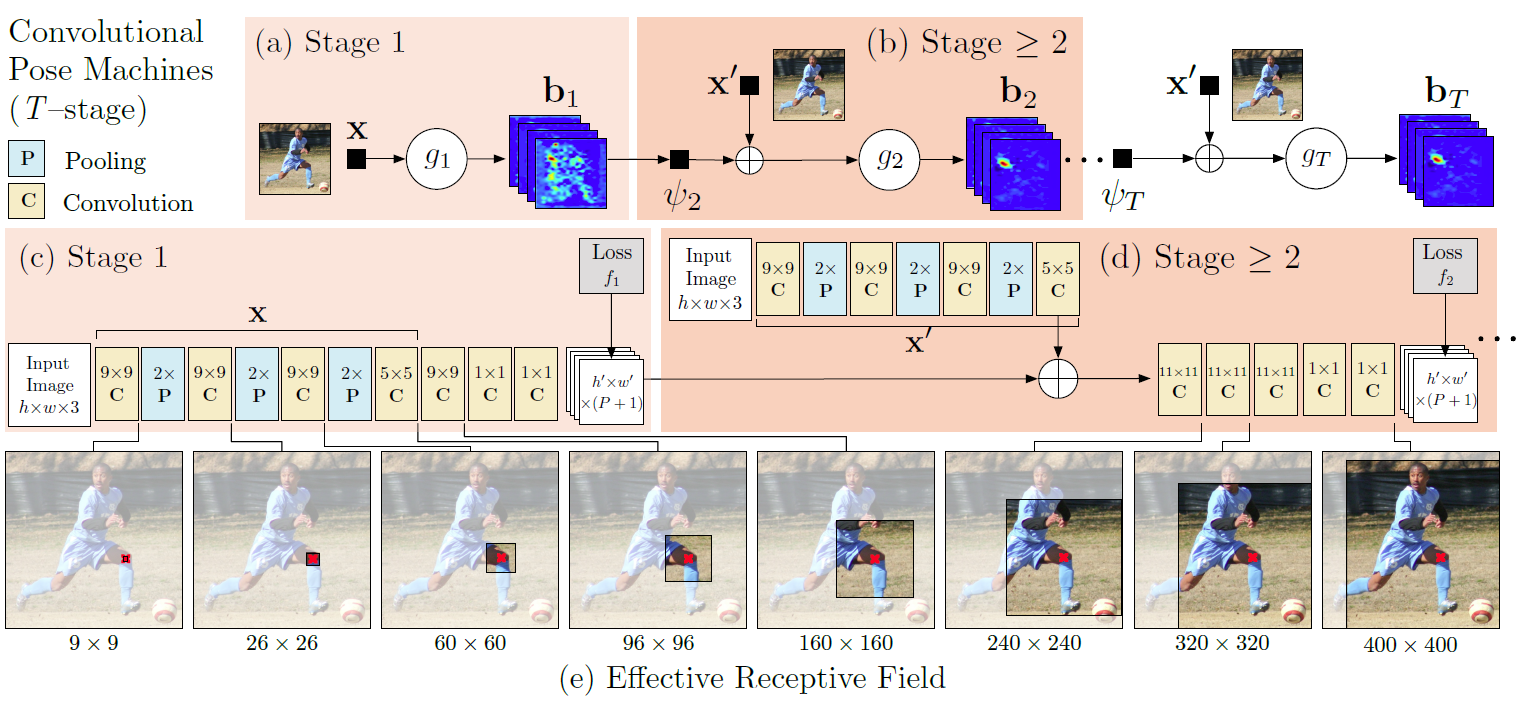
Code
class CPM(nn.Module):
def __init__(self):
super(CPM, self).__init__()
self.stage1 = CPMStage1()
self.stage2_image = CPMStage2Image()
self.stage2 = CPMStageT()
self.stage3 = CPMStageT()
self.stage4 = CPMStageT()
self.stage5 = CPMStageT()
self.stage6 = CPMStageT()
def forward(self, image, center_map):
stage1_maps = self.stage1(image)
stage2image_maps = self.stage2_image(image)
stage2_maps = self.stage2(stage1_maps, stage2image_maps, center_map)
stage3_maps = self.stage3(stage2_maps, stage2image_maps, center_map)
stage4_maps = self.stage4(stage3_maps, stage2image_maps, center_map)
stage5_maps = self.stage5(stage4_maps, stage2image_maps, center_map)
stage6_maps = self.stage6(stage5_maps, stage2image_maps, center_map)
return stage1_maps, stage2_maps, stage3_maps, stage4_maps, stage5_maps, stage6_mapsclass CPMStage1(nn.Module):
def __init__(self):
super(CPMStage1, self).__init__()
self.k = 14
self.conv1 = nn.Conv2d(3, 128, kernel_size=9, padding=4)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(128, 128, kernel_size=9, padding=4)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(128, 128, kernel_size=9, padding=4)
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv4 = nn.Conv2d(128, 32, kernel_size=5, padding=2)
self.conv5 = nn.Conv2d(32, 512, kernel_size=9, padding=4)
self.conv6 = nn.Conv2d(512, 512, kernel_size=1)
self.conv7 = nn.Conv2d(512, self.k + 1, kernel_size=1)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = F.relu(self.conv6(x))
x = self.conv7(x)
return xclass CPMStage2Image(nn.Module):
def __init__(self):
super(CPMStage2Image, self).__init__()
self.conv1 = nn.Conv2d(3, 128, kernel_size=9, padding=4)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(128, 128, kernel_size=9, padding=4)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv3 = nn.Conv2d(128, 128, kernel_size=9, padding=4)
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv4 = nn.Conv2d(128, 32, kernel_size=5, padding=2)
def forward(self, x):
x = self.pool1(F.relu(self.conv1(x)))
x = self.pool2(F.relu(self.conv2(x)))
x = self.pool3(F.relu(self.conv3(x)))
x = F.relu(self.conv4(x))
return xclass CPMStageT(nn.Module):
def __init__(self):
super(CPMStageT, self).__init__()
self.k = 14
self.conv_image = nn.Conv2d(self.k + 1, self.k + 1, kernel_size=5, padding=2)
self.conv1 = nn.Conv2d(32 + self.k + 2, 128, kernel_size=11, padding=5)
self.conv2 = nn.Conv2d(128, 128, kernel_size=11, padding=5)
self.conv3 = nn.Conv2d(128, 128, kernel_size=11, padding=5)
self.conv4 = nn.Conv2d(128, 128, kernel_size=1, padding=0)
self.conv5 = nn.Conv2d(128, self.k + 1, kernel_size=1, padding=0)
def forward(self, stage1_maps, stage2image_maps, center_map):
x = F.relu(self.conv_image(stage1_maps))
x = torch.cat([stage2image_maps, x, center_map], dim=1)
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.conv5(x)
return xResults
 Right ankle
Right ankle
 Right knee
Right knee
 Right hip
Right hip
 Left hip
Left hip
 Left knee
Left knee
 Left ankle
Left ankle
 Right wrist
Right wrist
 Right elbow
Right elbow
 Right shoulder
Right shoulder
 Left shoulder
Left shoulder
 Left elbow
Left elbow
 Left wrist
Left wrist
 Neck
Neck
 Head top
Head top

If you look closely at the Left Hip example or the Right Wrist example you will see that the model is able to improve its prediction in the subsequent stages by using a more larger context.
Improvements
Lots of well know pose estimation models are build on this model. They add the concept of Part Affinity Fields that are used to predict the relationship between the parts and using this approach they can also do multi-person pose estimation in real time. The famous OpenPose model is based on this architecture.
Learnings
I learned a lot of new things in this project.
- Increased my understanding of the PyTorch framework.
- Got better at reading machine learning papers and implementing them.
- Learned some tricks to debug and profile neural network models.
- Gained an intuitive understanding of different architectures.
In the future maybe I will revisit this problem and try more complex and current state of the art model and create a useful application using them.